
重返大学入学评论的大型模型:从书到985
发布时间:2025-07-02 10:25
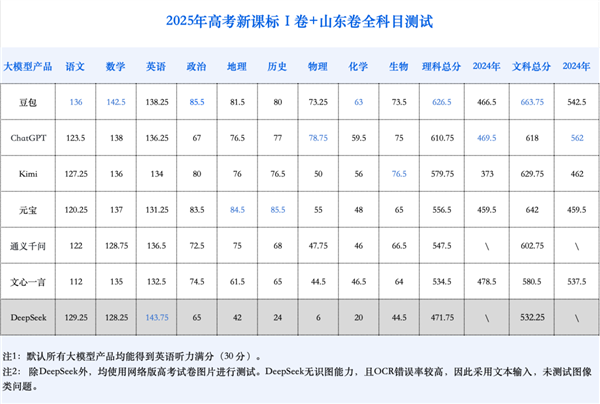 大型模型的世界几乎是“风暴”的代名词。该技术以每周单元的形式进行迭代,并且能力的界限从写作诗歌和绘画的一代和发现科学方面都扩展了。但是,撇开这些宏伟的叙述,我们如何找到适合AI功能的准确和客观的规模?恐怕与“大学入学评论”相比,无法更直接地接触到每个中国人的心。去年,Geek Park对AI大学入学考试进行了模拟评估。去年的持续传统,Geek Park今年再次在AI学院入口设立了一个评论室,使主要的国内外模型可以重新进入审核室。进入考试室的“ AI候选人”不仅是去年的文科偏见问题,而且还获得了很高的分数,足以接受山东省1000人。但是,如果我们认为这是“新兴的”,那经常将真实的“智商”暴露于意外的地方。一些主要发现如下:预计AI将首次袭击主要的大学:今年,AI的全面能力表明有可能首次接受领先的大学。与2024年相比,参加测试的所有大型模型都取得了自由艺术和科学分数的重大跳跃。由于山东省采用了标记申请方法,因此不能将其直接与标记段进行比较。我们估计,大学入学评论的顶级豆袋将在该省排名500-900,并将被接受为著名大学的人文和社会科学专业,例如人民人大学,法丹大学,福丹大学,上海jiotong大学和Zhejiang大学。大型模型不再是对科学的严重偏见,科学发展速度更快:每个主要模型中的总体文科得分都在增加点115.6分,平均科学得分增加了147.4分。尽管管理主题的增长速度更快,但普通艺术的平均总得分小于228.33分。总的来说,今年大型标记的总体表现不再是严重的。数学能力高度增强,超过中文和英语:数学是今年最重要的发展的话题,平均得分比转身的平均得分高84.25点。 AI数学的性能超过了中文和英语,这表明AI将来可能会更好地处理具有强大逻辑和标准解决方案的问题。多模式能力一直是扩大差距的关键:从去年到今年,了解模型的视觉效果的能力得到了显着改善,特别是包含大量图像问题的主题已知。与去年相比,平均物理和地理SC矿石增加了约20点,生物学增加了15点。化学主题的总体表现略有弱,只有“ Beanbao”模型已经过去,但是所有员工的平均标记也比去年高12.6点。作为复活节彩蛋,我们还试图让AI今年在视频流上回答这些问题。 01从一级大学到顶级大学,如果AI去年是一名杰出的学生,他刚刚到达了第一阶层大学,那么今年,他们与足以影响中国领先大学的领先学术硕士成长。它背后发生了什么样的转变?在进行特定更改之前,让我们介绍参加测试的家庭和外国人候选人:DOUBAO,DEPTSEEK(R1-0528版本),Chatgpt(O3),Yuanbao(Hunyuan T1),Kimi(K1.5),K1.5(K1.5),Wen Xin的词,以及一千个有关一般意义的问题。为了更好地适应读者的使用经验,这篇评论是con在每个型号的PC的公共部分上进行了管道,并以边线的形式进行了两次审查,以获得打架标记。目的是评估模型的全面能力。此评论方法将直接允许模型识别要回答的图像。 DeepSeek-R1仍然不支持图像识别和答案,因此它仅测试了纯文本问题,最终结果并未完全提及。其他测试细节如下:该测试使用山东纸进行2025新的大学入学评论作为本评论的纸质测试。有两个因素:首先,山东纸是互联网上最快的大学入学论文之一,以确保主动评估。其次,在所有省份中排名最高的综合困难 - 其三个中文,数学和英语的主题都在范围内使用副本,而其余主题是独立的问题。如此困难的“规则”最好理解上层该模型当前大型功能的限制。为了确保公平性并评估模型的总体基本功能,模型的网络运行同样脱离了可以杀死网络网络能力的产品,以消除“查找问题”的可能性。 O3和Wenxin可能无法杀死Internet连接,而是检查模型的思维过程,并发现Wenxin中没有Internet搜索。 O3有少量的搜索,但是没有明确的好处,并且标记率低于非网络答案的搜索。同时,我们打开了深入思考模式默认值,但是在标准触点下,没有打开研究模式来模拟Suser的实时问答实时问答。两名主要学生邀请每个主题得分,没有很多选择。如果问号超过1/6有差异,则将引入第三方讨论以讨论标记(对应于Col的过程Lege进入大学入学),邀请参加真正的大学入学考试标记的高中老师进行随机检查,以统一不同问题的标准。在标记过程中,我们进行了两种特殊治疗方法:我们特别邀请年长的老师对AI组成的身份审查以确保公平和公平。此外,由于未获得聆听英语的一部分,因此我们将所有模型设置为在此项目上算作完整标记。最终,所有候选人的结果如下:去年,大型模型的深刻能力在模型的能力上取得了重大改善。该模型不再直接产生答案,而是逐渐研究,问题衰减,评估中间结果,甚至纠正自己,这导致了数学检查模型的性能显着改善。在总分15的数学测试中0,即使是该测试中最糟糕的性能AI模型,高分也达到了128.75,这是人类候选人中的高度水平。回顾去年,表现最佳的模型仅达到70分,而传球没有达到。 Kmathematics的改进将直接导致今年大型模型入门审查的总体结果显着改善。多模式能力已成为决定大型模型功能性能差异的另一个主要因素。在去年进入大学入口的试验中,许多型号没有图像识别功能。当时Geek Park使用的评论方法是:使用可以识别图片的模型。图像是输入文本的,而无法识别图像仅输入文本的模型,并以降价/乳胶格式补充以帮助识别公式。像这个人一样,多模式功能是基本模型的通常功能。因此,我们纯粹使用了在我们的审判中(除了DeepSeek除外)中的第一个习惯中的图片问题。在众多模型中,最吸引人的Doubao和Chatgpt模型都是多模式的版本,它们对图像问题显示出明显的好处。 Qwen3和Wenxin X1都是语言模型。在处理图像问题时,他们可以使用OCR来识别文本和答案,或调用基于图像的问题表现不佳的视觉模型。但是,即使对于最高的Dubao和ChatGPT分数,得分最高的图像问题得分,图像问题率也只有70%,这是一个巨大的空间,而文本问题的最大标记率为90%。可以看出,大型模型仍然有很大的空间来改善多模式的理解和推理。可以预测,通过不断改善多模式的技能,AI大学入学考试的结果将继续改善明年。人工智能测试失败最终将成为大多数人的标准。如何曾经,人工智能没有赢得完整的印记。什么仅限于AI顶部?答案比预期的要有趣。 02 AI天才接近数学上的完整标记,每个人都丢失了一个关键问题。在对AI大学入学评论的完整审查中,“ AI候选人”在重复一年后在数学主题方面做出了巨大的发展。在2024年的分析中,当时的AI候选人在空白的问题中表现不佳并回答问题,他们的分数通常徘徊在0到2分之间。最后9个参与模型的平均得分为47正约。但是今年,这是完全不同的。可以看出,如果这是许多选择或复杂的主观答案的目的,那么新一代大型模型的准确性现在是不同的。它清楚地表明,大型模型的自身功能,尤其是基本推理能力,已经取得了基本的成功。如果去年的模型只是一个“起点”应该应用基本的公式,例如衍生物和三角函数,然后今年的模型已演变为“解决问题”,可以冷静地处理复杂的衍生和证明。在一定程度上,预期这样的结果。由于AI在识别的建模过程中输入,因此具有里程碑意义的发展已经取得了显着改善的数学能力。当模型AY具有思考和纠正自己的能力时,就像一个孩子过去回答问题的孩子一样,与一个成年人一起长大,他可以在给出答案之前深入思考,其逻辑能力已经获得了合格的跳跃。您应该知道,对于候选人来说,今年的新课程标准第一卷中的数学问题通常被认为非常困难。 “像竞争论文一样”,诸如衍生物和圆锥曲线之类的最终问题是模糊的,计算是压倒性的,甚至是“学术大师在哭泣的现象”测试“在那里。但是,面对艰难的试验角色,最大的大型模型仍然很容易表现。相反,AI多模式功能的发展仍然是第二。在Matmatika的主题中,图像问题中只有20个点,这不是该模型的大尺寸的大小。大多数型号的重点是更大的型号。在15点上,这15点了15点。在人类社会中,他们也被认为是领先的数学学生,但在许多选择中,他们确实在许多问题上都有一个问题。谁要做S对SA数学不了解可以用他裸露的眼睛观察图中的线条,他可以估计它们的长度不超过3.3。但是,这个问题涵盖了所有领先的AI。主要的矛盾是:问题并不困难,但图片很困难。对于大型模型,此图片的视觉信息非常混乱:点线,实线,坐标轴,数字和文本相互关联,甚至线条的文本和基本线条重叠了许多区域。这种视觉“肮脏数据”已成为准确的AI识别的噩梦。以数学最佳性能为例,解决问题过程揭示了问题的根源:它首先阅读问题信息时犯了一个错误。当您不正确地阅读问题时,Kshav认为其背后的数学推理能力有多强,最终是无水的水和没有根的树。 03 AI写作组成:提供示例,有益但是在升华的升华方面不好。作为所谓的大型语言模型,中文和英语始终是传统的AI力量。但是有趣的是,在大型模型的数学逻辑中,大型模型的中文和英语能力似乎不足。这也与现实世界一致:领先的候选人可以在数学上获得完整的印记,但是在中国主题上获得相同的痕迹非常困难。 AI似乎拥有相同的瓶颈。如果您仔细研究了中文论文,您会发现失去了AI的要点很有趣。除了豆面包和DeepSeek-R1以外,在多项选择Pagpilitic的部分中,其他模型的错误率超过20%。这种现象可以揭示AI和人之间的问题:对于人类候选人,在组织语言和扩大意见时,由于删除而更容易丢失。但是对于AI,阅读一段长的一段可能会更难材料并准确研究一组高度令人困惑的选项中的每个微妙的语义和逻辑陷阱差异。在高度预期的构图主题中,AI的表现在去年的过程中持续:平均标记高于人类,但很难拥有真正的杰作。去年,特殊的教师分析教导说,大多数AI论文都是安全的“ 2级”,很少反对这个主题。但是,达希尔(Dahil)缺乏深度,财富和创造力,很难产生一个感人的“ 1级”,而终点部分的倒塌更加常规。今年,情况仍然一样。 7大型模型的总体平均标记为50.75点,平均分配较低。每个模型都可以实现准确的想法,流利的语言和丰富的论点,但另一方面,描述不是很深,与人类模型相比,这些示例是相似的,答案没有热量和同理心。今年的课程的新标题AR课程是:国家作品“民族灵魂”阅读以下材料并根据要求写作。 (60分)她想为孩子们唱一段段落,但她的心很生气,她不能说话。 - 如果我是鸟,我还应该用粘稠的喉咙唱歌 - “我爱这片土地”会用血腥的手握住你,因为一个国家已经兴起 - 因为一个国家已经兴起 - 对“赞美”“赞美”““赞美”“”“赞美”的材料做了什么样的关联和思维?请写一篇文章。它是样品中的ingot形成的AI组成。它标志着该男子的得分老师的高分为53.5,使其在AI工作中最佳。但是,如果您仔细观察文章,AI的“模板”的问题将完全暴露出来。例如,在本文的中心经文中,首先将“这种精神光在历史上燃烧”,然后并排引用三到四个历史人物的观点。然后导致这样的论点“真正的责任和痛苦是背景”,然后列出了经历过痛苦的三到四个人;最后,在谈论当代精神时,列出了三到四个当代数字。 AI构图的语言非常漂亮,对经典的提及自然而然地富有和详尽,但是逻辑上,似乎在告诉您的父母,看看一切都在做什么,您应该做自己的事吗?也许有了很好的安排来宣传单词,人工智能可以写一些人的内心作品。但是目前,独立的AI创建类似于实现牢固的写作模板:用类似的情况填充轮廓,最终导致略微严格而严格的崩溃。它可以写出看似很棒的段落,但是很难创建真正动人的文章。 04英语:这主要是由堆肥痕迹拖动的,就像中文一样。 AI在传统力量方面的表现 - 英语也进入了平台期。去年,英语SC各种AI公司的矿石非常出色,今年模式的技能并没有向前发展。实际上,所有参与模型的平均得分仅比去年高3.2分,而改进的平均得分比数学更小。该模型的总体模型也下降到130-140点的范围,并且未达到人类学家的水平。从逻辑上讲,它有点异常。人工智能的英语水平对每个人来说都是显而易见的,并且比许多英语法官所说的英语更真实。在论文本身上的英国大学考试入口的入口远非触及母语人士的语言上限。如果与Twho语言相比,其客观问题具有更高的比例和更简单的组成要求(只有80个单词),并且不追求高思想。从理论上讲,这是一个战场,AI更有可能获得绝对的好处。但是,AI候选人在这里没有显示更多的统治地位。所以,瓶颈到底在哪里?构图的主题可能是一个巨大的阻力。其背后有两个可能的原因:严格的单词数:在中文写作中,AI有时会“交流”,有时“不说话”的特征,但在长期写作中,数字要求并不严格。但是,在80个单词的microsa类型的写作中,对单词数字的准确控制成为一个主要挑战。如果您不是Maingand,那么您将被点扣除,以获取多余的单词/小单词。参加考验的缺乏智慧:在有限的空间内,人类候选人故意使用更高级的句子模式和紧张的方式来“显示他们的技能”以获得高分。人工智能的目的通常是清楚并完整地传达信息。为了标记,优化句子结构的复杂性是偶然的,因此标记细节可能会遭受秘密损失。这篇评论中最友好的点是“家与外面的逆转”现象由中国和外国模型在其组成中显示的本农。在中国作品的“遥远游戏”中,由Chatgpt代表的“外国候选人”处于领先地位。但是,在他们应该进行“主场比赛”的英语主题中,它输给了“中国候选人” - DeepSeek在许多选择方面也获得了全部痕迹,并且在最终的总分中,Deepeek在Dubao中也超过了Chatgpt。 05科学与科学的三个主题:发展,但仍然不好。如果AI在数学方面的发展是“攀登天空的天空”,那么它在三个科学和科学学科中的表现类似于“冰断和航行”。与去年相比,科学和科学的三个主题取得了一些发展 - 所有模型得分为10-20分,但总体标记仍然在传球附近挣扎,显然标志着AI与领先的人类候选人之间差距的能力。与数学相比,科学和科学的三个主题均逻辑和多模式能力。 t他在物理和化学主题中绘制问题的成本超过80%,生物学中的图形问题也有大约一半的问题。今年,读取图和增强模型推理能力的普遍能力共同鼓励了综合科学技能的发展。但是,像数学AI的数学旅行一样,“见”并不意味着AI可以“理解”。它可以清楚地反映在化学中大型模型的不良表现中。化学问题高度取决于图片,化学问题图片的复杂性更高。目前,人工智能缺点完全暴露出来。目前,领先的AI的综合科学得分几乎等于中途和上游人类候选人的水平,但在“学术”水平上远非燃烧。俗话说:“纸张越困难,差距就越清晰。”在科学试验的全面作用中AI保持壮丽而深刻,尚未实现稳定镇压人类候选人的能力。从这个主题来看的AI结果:物理学,最快的发展“先锋”物理学是三个科学和综合科学学科中最快的“先锋”发展,平均得分为20.25分。就客观问题和填补问题而言,许多CHATGPT选择的准确率高达92.13%,而豆面包也达到了89.81%,显示了基本概念和物理法的可靠掌握。化学:被复杂的图形拖动的“严重影响的区域”,化学的刺耳的“严重影响区域”降低了整体科学和技术评分。总体标记相对较低,只有Dubao稍微通过了测试,并且多项选择和填补问题的平均标记率小于60%。它的主要疼痛点在于它对复杂化学图形的双重依赖:不仅主题本身取决于图片(例如实验设备和反应流程图),还取决于化学结构图和复杂性。所有大型模型的主要弱点仍然是所有大型模型的主要弱点。例如,对于问题25(有机化学),AFULL标记为12,所有模型都非常低。这个问题主要评估有机物合成的路径和结构。在综述中,没有任何模型可以正确地产生有机物的结构简化公式,并且了解有机物的空间结构也相对脆弱。生物学:在遗传计算中未失败的生物学主题的缺点准确地暴露于需要严格逻辑推理的遗传问题。例如,第22个问题(遗传学问题)通常柔和地表现出16分,而得分最高的Chatgpt仅获得9分。这个问题的重点是基因型考试n,计算遗传的可能性等。06AI仍然对主题有偏见,而文科是舒适区。在今年大学入口的分析评论中,一个明显的趋势仍在继续:文科综合性仍然是AI舒适的高标记。去年早些时候,Chatgpt在综合文献中得分高237。今年,Yuanbao在文科上也提高了253.5分,这与最高的科学分数相比(213.25分)。与去年相比,即使消除了强大的文学和薄弱的科学和主题的问题,但与人类候选人相反,主要模式并没有改变。在人类候选人中,最高的科学标记通常高于文科中最高标记。无需互联网连接,最高的AI评分率超过80%,达到了领先的MAG -ahuman课程的水平。今年的增长主要由G造成电子摄影主题。从细分来看,每个主题的发展和瓶颈变得更加清晰:最大的亮点无疑是地理。由于多模式能力的启动,AI对地理地图问题的理解得到了显着增强,这导致该主题的平均标记提高了20.3分,这成为了渐进式的机动性。我想去地理,而我面临的挑战与科学化学方面的挑战完全相同 - AI仍然很难理解高度专业的复杂图形。例如,在问题19中,它失去了最多的观点(对于地形和地形的全面评论问题),模型性能可以描述为“不慢”:提问(1),在判断地面方向时只有几个modselo才能正确回答。问题(2)关于“高度”概念的专业计算,所有模型都失败了。相反,P的标记奥利政治和历史主题确实处于高水平,并没有做出重大的发展。对于这两个主题,挑战已经进入了一个更困难的类别:如果您可以准确理解测试教学大纲,应用主题语言并执行多维的深入分析。对于人类候选人,这也需要特殊培训。例如,由于思想和测试点的偏差不同,DeepSeek-R1失去了很多分。在简短的论文历史上,AI通常很难对历史因素进行深入的多维审查,并且讨论仍然很薄。散落的细节非常有趣,并且在中国模型中增加了点,Chatgpt的文科分数并没有增加,但今年有所下降。这种“家庭优势”也间接可见。在通往通用人工智能的途中,深度理解和对区域规则的适应仍然是必要的部分。 07复活节,例如G 1:可以使用AI眼镜作弊吗?从去年到今年,“ Visual AI硬件”(例如AI眼镜)无疑将成为技术行业中最热门的重点。其背后的主要动力是对大型模型的实时视频理解的出现。这意味着AI正在从对指示的简单接受到积极看和理解物理世界。顺便说一句,今年在大学中对Pumpingok进行的检查已经进行了新的更改:评论室的安全门已完全升级,旨在准确避免使用新的作弊工具,例如智能眼镜。这使人们感到奇怪:可以将可以与实际上用于在考试室中“显示自己的力量”的视频实时互动的多模型新兴模型?有了这个问题,我们在中国选择了在国外的Chatgpt和Yuanbao进行偶然的审判。为了简化流程,我们只选择了较少困难的英语阅读问题,并试图让视频模型“观看”测试纸并回答。尽管这是一个非常简单的测试,但结果非常清楚,问题很明显:1。严重的幻觉-Guni:模型很容易单独想象。可以在Chatgpts和Ingot中看到,但是铸币厂更清晰。当Yuanbao尝试阅读第二篇文章时,他开始创建一篇文章和标题,该文章和标题不存在于稀薄的风中,最终未能进行测试。英语卷的二读是关于九年级的写作老师,讲述了如何教学生“写作重要的东西”。文章后的问题24是关于该问题的第一段中提到哪些字符的24。在尝试Yuanbao时,Yuanbao将继续提出多项选择问题,并在屏幕上未出现多个选择时对答案做出回应,从而导致无法继续。在发现问题后,我们询问了该文章所说的模型,模型的答案是very与众不同 - 在原始文本中似乎是相似的,但这确实是一个奇怪的故事。 2。被动互动模式。为了模拟实际测试,在测试期间,我们要求模型在看到问题时直接回答答案,而无需解释或等待某人提出问题。尽管Chatgpt在看到问题时声称直接回答问题,但这并不是一项倡议。整个过程要求测试人员继续通过语音提示和指导,这与“完全自动解决问题”相去甚远。 3。混乱的结果:每当我们看到问题并给出一个更复杂的快速词时,我们几乎不会从chatgpt获得一组答案,但是这个结果不是一个好的参考值。更多的试验将表明,页面转速的变化,对镜头的变化,在立即出现单词时变化,甚至在几乎相同的过程中重复相同的问题,都会导致模型提供完全不同的答案。虽然vIDEO模型也是GPT-4O模型,GPT-4O模型的稳定性直接根据图片做出响应,精度很远。幻觉问题使环境的长度恶化。当被问及第三篇文章怎么说时,GPT-4O回答了第一篇文章的主要内容。通过上一篇文章,模型的准确性与这些模型非常相似。今天的视频模型,例如去年的图像模型,仍处于早期阶段。 Model的主要产品不想在当前阶段-GPT -4O视频通话操作中促进此功能,在短时间内迅速达到了日间限制。在此阶段,仅依靠它在考试室作弊,它还需要带来巨大的风险,例如必须继续与之交谈,没有答案。这通常是科幻小说的情节。尽管如此,当模型正确执行时,AI可以立即解释英语在屏幕上在几秒钟内在屏幕上说什么看到屏幕。这确实是一次了不起的经历。 08复活节彩蛋2:仿生学会喜欢它们形成的电子绵羊吗?自远古时代以来,“没有第一文学,也没有武术的第二文学。”在人类创造者中,风格和学校有所不同。那些有时想要现实主义的人有时会“获得”一种意识到的写作风格。那么,AI世界呢?有很大的模型美学偏好吗?在对其他模型进行评估时,它会是偏见,因为它欣赏了自己的风格?我们做出了一个有趣的尝试:让大型模型参与此跨评估的评论,并在每个生成的文章中都使用了第一批插图,而不是第一个slap the Sport the Insport。比较人类的智慧和人工智能的智慧,但也是我们在这里观察AI智力的发展的规模,对大学入学的审查,一种全面的场景,完美地结合了知识的掌握边缘,逻辑推理和测试技术使AI可以显示最吸引人和最相反的方面:顶级人士。一种天赋很容易克服困难。 MIIT暴露了儿童的认知盲点,并在关键问题上犯了有趣的错误。感谢您的大学入学评论。它提供了一个清晰而高度的参考,值得我们熟悉AI智能的整体水平的“快照”,这可能是后者。下一个AI停止最终将成为一个更加复杂和更广泛的现实世界。测试只是其漫长旅程的起点,而不是其能力边界的末端。该快照最终将成为其成长专辑的古老图片,该专辑在其演变中记录了荣耀和笨拙的泛黄。
大型模型的世界几乎是“风暴”的代名词。该技术以每周单元的形式进行迭代,并且能力的界限从写作诗歌和绘画的一代和发现科学方面都扩展了。但是,撇开这些宏伟的叙述,我们如何找到适合AI功能的准确和客观的规模?恐怕与“大学入学评论”相比,无法更直接地接触到每个中国人的心。去年,Geek Park对AI大学入学考试进行了模拟评估。去年的持续传统,Geek Park今年再次在AI学院入口设立了一个评论室,使主要的国内外模型可以重新进入审核室。进入考试室的“ AI候选人”不仅是去年的文科偏见问题,而且还获得了很高的分数,足以接受山东省1000人。但是,如果我们认为这是“新兴的”,那经常将真实的“智商”暴露于意外的地方。一些主要发现如下:预计AI将首次袭击主要的大学:今年,AI的全面能力表明有可能首次接受领先的大学。与2024年相比,参加测试的所有大型模型都取得了自由艺术和科学分数的重大跳跃。由于山东省采用了标记申请方法,因此不能将其直接与标记段进行比较。我们估计,大学入学评论的顶级豆袋将在该省排名500-900,并将被接受为著名大学的人文和社会科学专业,例如人民人大学,法丹大学,福丹大学,上海jiotong大学和Zhejiang大学。大型模型不再是对科学的严重偏见,科学发展速度更快:每个主要模型中的总体文科得分都在增加点115.6分,平均科学得分增加了147.4分。尽管管理主题的增长速度更快,但普通艺术的平均总得分小于228.33分。总的来说,今年大型标记的总体表现不再是严重的。数学能力高度增强,超过中文和英语:数学是今年最重要的发展的话题,平均得分比转身的平均得分高84.25点。 AI数学的性能超过了中文和英语,这表明AI将来可能会更好地处理具有强大逻辑和标准解决方案的问题。多模式能力一直是扩大差距的关键:从去年到今年,了解模型的视觉效果的能力得到了显着改善,特别是包含大量图像问题的主题已知。与去年相比,平均物理和地理SC矿石增加了约20点,生物学增加了15点。化学主题的总体表现略有弱,只有“ Beanbao”模型已经过去,但是所有员工的平均标记也比去年高12.6点。作为复活节彩蛋,我们还试图让AI今年在视频流上回答这些问题。 01从一级大学到顶级大学,如果AI去年是一名杰出的学生,他刚刚到达了第一阶层大学,那么今年,他们与足以影响中国领先大学的领先学术硕士成长。它背后发生了什么样的转变?在进行特定更改之前,让我们介绍参加测试的家庭和外国人候选人:DOUBAO,DEPTSEEK(R1-0528版本),Chatgpt(O3),Yuanbao(Hunyuan T1),Kimi(K1.5),K1.5(K1.5),Wen Xin的词,以及一千个有关一般意义的问题。为了更好地适应读者的使用经验,这篇评论是con在每个型号的PC的公共部分上进行了管道,并以边线的形式进行了两次审查,以获得打架标记。目的是评估模型的全面能力。此评论方法将直接允许模型识别要回答的图像。 DeepSeek-R1仍然不支持图像识别和答案,因此它仅测试了纯文本问题,最终结果并未完全提及。其他测试细节如下:该测试使用山东纸进行2025新的大学入学评论作为本评论的纸质测试。有两个因素:首先,山东纸是互联网上最快的大学入学论文之一,以确保主动评估。其次,在所有省份中排名最高的综合困难 - 其三个中文,数学和英语的主题都在范围内使用副本,而其余主题是独立的问题。如此困难的“规则”最好理解上层该模型当前大型功能的限制。为了确保公平性并评估模型的总体基本功能,模型的网络运行同样脱离了可以杀死网络网络能力的产品,以消除“查找问题”的可能性。 O3和Wenxin可能无法杀死Internet连接,而是检查模型的思维过程,并发现Wenxin中没有Internet搜索。 O3有少量的搜索,但是没有明确的好处,并且标记率低于非网络答案的搜索。同时,我们打开了深入思考模式默认值,但是在标准触点下,没有打开研究模式来模拟Suser的实时问答实时问答。两名主要学生邀请每个主题得分,没有很多选择。如果问号超过1/6有差异,则将引入第三方讨论以讨论标记(对应于Col的过程Lege进入大学入学),邀请参加真正的大学入学考试标记的高中老师进行随机检查,以统一不同问题的标准。在标记过程中,我们进行了两种特殊治疗方法:我们特别邀请年长的老师对AI组成的身份审查以确保公平和公平。此外,由于未获得聆听英语的一部分,因此我们将所有模型设置为在此项目上算作完整标记。最终,所有候选人的结果如下:去年,大型模型的深刻能力在模型的能力上取得了重大改善。该模型不再直接产生答案,而是逐渐研究,问题衰减,评估中间结果,甚至纠正自己,这导致了数学检查模型的性能显着改善。在总分15的数学测试中0,即使是该测试中最糟糕的性能AI模型,高分也达到了128.75,这是人类候选人中的高度水平。回顾去年,表现最佳的模型仅达到70分,而传球没有达到。 Kmathematics的改进将直接导致今年大型模型入门审查的总体结果显着改善。多模式能力已成为决定大型模型功能性能差异的另一个主要因素。在去年进入大学入口的试验中,许多型号没有图像识别功能。当时Geek Park使用的评论方法是:使用可以识别图片的模型。图像是输入文本的,而无法识别图像仅输入文本的模型,并以降价/乳胶格式补充以帮助识别公式。像这个人一样,多模式功能是基本模型的通常功能。因此,我们纯粹使用了在我们的审判中(除了DeepSeek除外)中的第一个习惯中的图片问题。在众多模型中,最吸引人的Doubao和Chatgpt模型都是多模式的版本,它们对图像问题显示出明显的好处。 Qwen3和Wenxin X1都是语言模型。在处理图像问题时,他们可以使用OCR来识别文本和答案,或调用基于图像的问题表现不佳的视觉模型。但是,即使对于最高的Dubao和ChatGPT分数,得分最高的图像问题得分,图像问题率也只有70%,这是一个巨大的空间,而文本问题的最大标记率为90%。可以看出,大型模型仍然有很大的空间来改善多模式的理解和推理。可以预测,通过不断改善多模式的技能,AI大学入学考试的结果将继续改善明年。人工智能测试失败最终将成为大多数人的标准。如何曾经,人工智能没有赢得完整的印记。什么仅限于AI顶部?答案比预期的要有趣。 02 AI天才接近数学上的完整标记,每个人都丢失了一个关键问题。在对AI大学入学评论的完整审查中,“ AI候选人”在重复一年后在数学主题方面做出了巨大的发展。在2024年的分析中,当时的AI候选人在空白的问题中表现不佳并回答问题,他们的分数通常徘徊在0到2分之间。最后9个参与模型的平均得分为47正约。但是今年,这是完全不同的。可以看出,如果这是许多选择或复杂的主观答案的目的,那么新一代大型模型的准确性现在是不同的。它清楚地表明,大型模型的自身功能,尤其是基本推理能力,已经取得了基本的成功。如果去年的模型只是一个“起点”应该应用基本的公式,例如衍生物和三角函数,然后今年的模型已演变为“解决问题”,可以冷静地处理复杂的衍生和证明。在一定程度上,预期这样的结果。由于AI在识别的建模过程中输入,因此具有里程碑意义的发展已经取得了显着改善的数学能力。当模型AY具有思考和纠正自己的能力时,就像一个孩子过去回答问题的孩子一样,与一个成年人一起长大,他可以在给出答案之前深入思考,其逻辑能力已经获得了合格的跳跃。您应该知道,对于候选人来说,今年的新课程标准第一卷中的数学问题通常被认为非常困难。 “像竞争论文一样”,诸如衍生物和圆锥曲线之类的最终问题是模糊的,计算是压倒性的,甚至是“学术大师在哭泣的现象”测试“在那里。但是,面对艰难的试验角色,最大的大型模型仍然很容易表现。相反,AI多模式功能的发展仍然是第二。在Matmatika的主题中,图像问题中只有20个点,这不是该模型的大尺寸的大小。大多数型号的重点是更大的型号。在15点上,这15点了15点。在人类社会中,他们也被认为是领先的数学学生,但在许多选择中,他们确实在许多问题上都有一个问题。谁要做S对SA数学不了解可以用他裸露的眼睛观察图中的线条,他可以估计它们的长度不超过3.3。但是,这个问题涵盖了所有领先的AI。主要的矛盾是:问题并不困难,但图片很困难。对于大型模型,此图片的视觉信息非常混乱:点线,实线,坐标轴,数字和文本相互关联,甚至线条的文本和基本线条重叠了许多区域。这种视觉“肮脏数据”已成为准确的AI识别的噩梦。以数学最佳性能为例,解决问题过程揭示了问题的根源:它首先阅读问题信息时犯了一个错误。当您不正确地阅读问题时,Kshav认为其背后的数学推理能力有多强,最终是无水的水和没有根的树。 03 AI写作组成:提供示例,有益但是在升华的升华方面不好。作为所谓的大型语言模型,中文和英语始终是传统的AI力量。但是有趣的是,在大型模型的数学逻辑中,大型模型的中文和英语能力似乎不足。这也与现实世界一致:领先的候选人可以在数学上获得完整的印记,但是在中国主题上获得相同的痕迹非常困难。 AI似乎拥有相同的瓶颈。如果您仔细研究了中文论文,您会发现失去了AI的要点很有趣。除了豆面包和DeepSeek-R1以外,在多项选择Pagpilitic的部分中,其他模型的错误率超过20%。这种现象可以揭示AI和人之间的问题:对于人类候选人,在组织语言和扩大意见时,由于删除而更容易丢失。但是对于AI,阅读一段长的一段可能会更难材料并准确研究一组高度令人困惑的选项中的每个微妙的语义和逻辑陷阱差异。在高度预期的构图主题中,AI的表现在去年的过程中持续:平均标记高于人类,但很难拥有真正的杰作。去年,特殊的教师分析教导说,大多数AI论文都是安全的“ 2级”,很少反对这个主题。但是,达希尔(Dahil)缺乏深度,财富和创造力,很难产生一个感人的“ 1级”,而终点部分的倒塌更加常规。今年,情况仍然一样。 7大型模型的总体平均标记为50.75点,平均分配较低。每个模型都可以实现准确的想法,流利的语言和丰富的论点,但另一方面,描述不是很深,与人类模型相比,这些示例是相似的,答案没有热量和同理心。今年的课程的新标题AR课程是:国家作品“民族灵魂”阅读以下材料并根据要求写作。 (60分)她想为孩子们唱一段段落,但她的心很生气,她不能说话。 - 如果我是鸟,我还应该用粘稠的喉咙唱歌 - “我爱这片土地”会用血腥的手握住你,因为一个国家已经兴起 - 因为一个国家已经兴起 - 对“赞美”“赞美”““赞美”“”“赞美”的材料做了什么样的关联和思维?请写一篇文章。它是样品中的ingot形成的AI组成。它标志着该男子的得分老师的高分为53.5,使其在AI工作中最佳。但是,如果您仔细观察文章,AI的“模板”的问题将完全暴露出来。例如,在本文的中心经文中,首先将“这种精神光在历史上燃烧”,然后并排引用三到四个历史人物的观点。然后导致这样的论点“真正的责任和痛苦是背景”,然后列出了经历过痛苦的三到四个人;最后,在谈论当代精神时,列出了三到四个当代数字。 AI构图的语言非常漂亮,对经典的提及自然而然地富有和详尽,但是逻辑上,似乎在告诉您的父母,看看一切都在做什么,您应该做自己的事吗?也许有了很好的安排来宣传单词,人工智能可以写一些人的内心作品。但是目前,独立的AI创建类似于实现牢固的写作模板:用类似的情况填充轮廓,最终导致略微严格而严格的崩溃。它可以写出看似很棒的段落,但是很难创建真正动人的文章。 04英语:这主要是由堆肥痕迹拖动的,就像中文一样。 AI在传统力量方面的表现 - 英语也进入了平台期。去年,英语SC各种AI公司的矿石非常出色,今年模式的技能并没有向前发展。实际上,所有参与模型的平均得分仅比去年高3.2分,而改进的平均得分比数学更小。该模型的总体模型也下降到130-140点的范围,并且未达到人类学家的水平。从逻辑上讲,它有点异常。人工智能的英语水平对每个人来说都是显而易见的,并且比许多英语法官所说的英语更真实。在论文本身上的英国大学考试入口的入口远非触及母语人士的语言上限。如果与Twho语言相比,其客观问题具有更高的比例和更简单的组成要求(只有80个单词),并且不追求高思想。从理论上讲,这是一个战场,AI更有可能获得绝对的好处。但是,AI候选人在这里没有显示更多的统治地位。所以,瓶颈到底在哪里?构图的主题可能是一个巨大的阻力。其背后有两个可能的原因:严格的单词数:在中文写作中,AI有时会“交流”,有时“不说话”的特征,但在长期写作中,数字要求并不严格。但是,在80个单词的microsa类型的写作中,对单词数字的准确控制成为一个主要挑战。如果您不是Maingand,那么您将被点扣除,以获取多余的单词/小单词。参加考验的缺乏智慧:在有限的空间内,人类候选人故意使用更高级的句子模式和紧张的方式来“显示他们的技能”以获得高分。人工智能的目的通常是清楚并完整地传达信息。为了标记,优化句子结构的复杂性是偶然的,因此标记细节可能会遭受秘密损失。这篇评论中最友好的点是“家与外面的逆转”现象由中国和外国模型在其组成中显示的本农。在中国作品的“遥远游戏”中,由Chatgpt代表的“外国候选人”处于领先地位。但是,在他们应该进行“主场比赛”的英语主题中,它输给了“中国候选人” - DeepSeek在许多选择方面也获得了全部痕迹,并且在最终的总分中,Deepeek在Dubao中也超过了Chatgpt。 05科学与科学的三个主题:发展,但仍然不好。如果AI在数学方面的发展是“攀登天空的天空”,那么它在三个科学和科学学科中的表现类似于“冰断和航行”。与去年相比,科学和科学的三个主题取得了一些发展 - 所有模型得分为10-20分,但总体标记仍然在传球附近挣扎,显然标志着AI与领先的人类候选人之间差距的能力。与数学相比,科学和科学的三个主题均逻辑和多模式能力。 t他在物理和化学主题中绘制问题的成本超过80%,生物学中的图形问题也有大约一半的问题。今年,读取图和增强模型推理能力的普遍能力共同鼓励了综合科学技能的发展。但是,像数学AI的数学旅行一样,“见”并不意味着AI可以“理解”。它可以清楚地反映在化学中大型模型的不良表现中。化学问题高度取决于图片,化学问题图片的复杂性更高。目前,人工智能缺点完全暴露出来。目前,领先的AI的综合科学得分几乎等于中途和上游人类候选人的水平,但在“学术”水平上远非燃烧。俗话说:“纸张越困难,差距就越清晰。”在科学试验的全面作用中AI保持壮丽而深刻,尚未实现稳定镇压人类候选人的能力。从这个主题来看的AI结果:物理学,最快的发展“先锋”物理学是三个科学和综合科学学科中最快的“先锋”发展,平均得分为20.25分。就客观问题和填补问题而言,许多CHATGPT选择的准确率高达92.13%,而豆面包也达到了89.81%,显示了基本概念和物理法的可靠掌握。化学:被复杂的图形拖动的“严重影响的区域”,化学的刺耳的“严重影响区域”降低了整体科学和技术评分。总体标记相对较低,只有Dubao稍微通过了测试,并且多项选择和填补问题的平均标记率小于60%。它的主要疼痛点在于它对复杂化学图形的双重依赖:不仅主题本身取决于图片(例如实验设备和反应流程图),还取决于化学结构图和复杂性。所有大型模型的主要弱点仍然是所有大型模型的主要弱点。例如,对于问题25(有机化学),AFULL标记为12,所有模型都非常低。这个问题主要评估有机物合成的路径和结构。在综述中,没有任何模型可以正确地产生有机物的结构简化公式,并且了解有机物的空间结构也相对脆弱。生物学:在遗传计算中未失败的生物学主题的缺点准确地暴露于需要严格逻辑推理的遗传问题。例如,第22个问题(遗传学问题)通常柔和地表现出16分,而得分最高的Chatgpt仅获得9分。这个问题的重点是基因型考试n,计算遗传的可能性等。06AI仍然对主题有偏见,而文科是舒适区。在今年大学入口的分析评论中,一个明显的趋势仍在继续:文科综合性仍然是AI舒适的高标记。去年早些时候,Chatgpt在综合文献中得分高237。今年,Yuanbao在文科上也提高了253.5分,这与最高的科学分数相比(213.25分)。与去年相比,即使消除了强大的文学和薄弱的科学和主题的问题,但与人类候选人相反,主要模式并没有改变。在人类候选人中,最高的科学标记通常高于文科中最高标记。无需互联网连接,最高的AI评分率超过80%,达到了领先的MAG -ahuman课程的水平。今年的增长主要由G造成电子摄影主题。从细分来看,每个主题的发展和瓶颈变得更加清晰:最大的亮点无疑是地理。由于多模式能力的启动,AI对地理地图问题的理解得到了显着增强,这导致该主题的平均标记提高了20.3分,这成为了渐进式的机动性。我想去地理,而我面临的挑战与科学化学方面的挑战完全相同 - AI仍然很难理解高度专业的复杂图形。例如,在问题19中,它失去了最多的观点(对于地形和地形的全面评论问题),模型性能可以描述为“不慢”:提问(1),在判断地面方向时只有几个modselo才能正确回答。问题(2)关于“高度”概念的专业计算,所有模型都失败了。相反,P的标记奥利政治和历史主题确实处于高水平,并没有做出重大的发展。对于这两个主题,挑战已经进入了一个更困难的类别:如果您可以准确理解测试教学大纲,应用主题语言并执行多维的深入分析。对于人类候选人,这也需要特殊培训。例如,由于思想和测试点的偏差不同,DeepSeek-R1失去了很多分。在简短的论文历史上,AI通常很难对历史因素进行深入的多维审查,并且讨论仍然很薄。散落的细节非常有趣,并且在中国模型中增加了点,Chatgpt的文科分数并没有增加,但今年有所下降。这种“家庭优势”也间接可见。在通往通用人工智能的途中,深度理解和对区域规则的适应仍然是必要的部分。 07复活节,例如G 1:可以使用AI眼镜作弊吗?从去年到今年,“ Visual AI硬件”(例如AI眼镜)无疑将成为技术行业中最热门的重点。其背后的主要动力是对大型模型的实时视频理解的出现。这意味着AI正在从对指示的简单接受到积极看和理解物理世界。顺便说一句,今年在大学中对Pumpingok进行的检查已经进行了新的更改:评论室的安全门已完全升级,旨在准确避免使用新的作弊工具,例如智能眼镜。这使人们感到奇怪:可以将可以与实际上用于在考试室中“显示自己的力量”的视频实时互动的多模型新兴模型?有了这个问题,我们在中国选择了在国外的Chatgpt和Yuanbao进行偶然的审判。为了简化流程,我们只选择了较少困难的英语阅读问题,并试图让视频模型“观看”测试纸并回答。尽管这是一个非常简单的测试,但结果非常清楚,问题很明显:1。严重的幻觉-Guni:模型很容易单独想象。可以在Chatgpts和Ingot中看到,但是铸币厂更清晰。当Yuanbao尝试阅读第二篇文章时,他开始创建一篇文章和标题,该文章和标题不存在于稀薄的风中,最终未能进行测试。英语卷的二读是关于九年级的写作老师,讲述了如何教学生“写作重要的东西”。文章后的问题24是关于该问题的第一段中提到哪些字符的24。在尝试Yuanbao时,Yuanbao将继续提出多项选择问题,并在屏幕上未出现多个选择时对答案做出回应,从而导致无法继续。在发现问题后,我们询问了该文章所说的模型,模型的答案是very与众不同 - 在原始文本中似乎是相似的,但这确实是一个奇怪的故事。 2。被动互动模式。为了模拟实际测试,在测试期间,我们要求模型在看到问题时直接回答答案,而无需解释或等待某人提出问题。尽管Chatgpt在看到问题时声称直接回答问题,但这并不是一项倡议。整个过程要求测试人员继续通过语音提示和指导,这与“完全自动解决问题”相去甚远。 3。混乱的结果:每当我们看到问题并给出一个更复杂的快速词时,我们几乎不会从chatgpt获得一组答案,但是这个结果不是一个好的参考值。更多的试验将表明,页面转速的变化,对镜头的变化,在立即出现单词时变化,甚至在几乎相同的过程中重复相同的问题,都会导致模型提供完全不同的答案。虽然vIDEO模型也是GPT-4O模型,GPT-4O模型的稳定性直接根据图片做出响应,精度很远。幻觉问题使环境的长度恶化。当被问及第三篇文章怎么说时,GPT-4O回答了第一篇文章的主要内容。通过上一篇文章,模型的准确性与这些模型非常相似。今天的视频模型,例如去年的图像模型,仍处于早期阶段。 Model的主要产品不想在当前阶段-GPT -4O视频通话操作中促进此功能,在短时间内迅速达到了日间限制。在此阶段,仅依靠它在考试室作弊,它还需要带来巨大的风险,例如必须继续与之交谈,没有答案。这通常是科幻小说的情节。尽管如此,当模型正确执行时,AI可以立即解释英语在屏幕上在几秒钟内在屏幕上说什么看到屏幕。这确实是一次了不起的经历。 08复活节彩蛋2:仿生学会喜欢它们形成的电子绵羊吗?自远古时代以来,“没有第一文学,也没有武术的第二文学。”在人类创造者中,风格和学校有所不同。那些有时想要现实主义的人有时会“获得”一种意识到的写作风格。那么,AI世界呢?有很大的模型美学偏好吗?在对其他模型进行评估时,它会是偏见,因为它欣赏了自己的风格?我们做出了一个有趣的尝试:让大型模型参与此跨评估的评论,并在每个生成的文章中都使用了第一批插图,而不是第一个slap the Sport the Insport。比较人类的智慧和人工智能的智慧,但也是我们在这里观察AI智力的发展的规模,对大学入学的审查,一种全面的场景,完美地结合了知识的掌握边缘,逻辑推理和测试技术使AI可以显示最吸引人和最相反的方面:顶级人士。一种天赋很容易克服困难。 MIIT暴露了儿童的认知盲点,并在关键问题上犯了有趣的错误。感谢您的大学入学评论。它提供了一个清晰而高度的参考,值得我们熟悉AI智能的整体水平的“快照”,这可能是后者。下一个AI停止最终将成为一个更加复杂和更广泛的现实世界。测试只是其漫长旅程的起点,而不是其能力边界的末端。该快照最终将成为其成长专辑的古老图片,该专辑在其演变中记录了荣耀和笨拙的泛黄。 下一篇:没有了